It's now just over 10 years since webchick handed maintainership of the Module Builder project over to me. I can still remember nervously approaching her at the end of a day at DrupalCon 2008, outside the building where people were chatting, and asking her if she'd had time to look at the patches I'd posted for it. I was at my first DrupalCon; she'd just been named as the core co-maintainer for the work about to start on Drupal 7. No, she hadn't, she said, and she instantly came to the conclusion that she'd never have the time to look at them, and so got her laptop out of her rucksack and there and then edited the project node to make me the maintainer.
Given the longevity of the project, I am often surprised when I talk to people that they don't know what its crucial advantage is over the other Drupal code generating tools that now also exist. Drupal Code Builder, as it's now called, is fundamentally different from Drupal Console's Generator command, and the Drupal Code Generator library that’s included in Drush 9.
I feel that perhaps this requires a buzzword, to make it more noticeable and memorable.
So here is one: Drupal Code Builder is an analytical code generator.
I'm going to add a second one: the Drupal Code Builder Drush commands and Module Builder (which still exists, though is now just module that provides a Drupal-based UI for the Drupal Code Builder library) are adaptive.
What do I mean by those?
When you first install Drupal Code Builder, it has no information about Drupal hooks, or plugin types, or services. There is no data in the codebase on how to generate a hook_form_alter() implementation, or a Block plugin, or how to inject the entity_type.manager service.
Before you can generate code, you need to run a command or submit an admin form which will analyse your entire codebase, and store the resulting data on hooks, plugin types, services, and other Drupal structures (the list of what is analysed keeps growing.).
The consequence of this is huge: Drupal Code Builder is not limited to core hooks, or to the hooks that it's been programmed for. Drupal Code Builder knows all the hooks in your codebase: from core, from contrib module, even from any of your own custom code that invents hooks.
Now repeat that statement for plugin types, for services, and so on.
And that analysis process can, and should, be repeated when you download a new module, because then any Drupal structures (hooks, plugin types, etc) that are defined in new modules gets added to the list of what Drupal Code Builder can generate.
This means that you can use Drupal Code Builder to do something like this:
- Generate a new plugin type. This creates a plugin manager service class and declaration, an annotation class that defines the plugin annotation, and an interface and base class for the plugins.
- Re-run DCB's analysis.
- Generate a plugin of the type you've just made.
When I say that this technique of analysis makes Drupal Coder Builder more powerful than other code generators, I'm not even blowing my own trumpet: the module I was handed in 2008 did the same. Back then in the Drupal 6 era is needed to connect to drupal.org's CVS repository to download the api.php files that document a module's hooks (which is why the Drush command for updating the code analysis prior to Drush 9 is called mb-download). For Drupal 7, the api.php files were moved into the core Drupal codebase, so from that point the process would scan the site's codebase directly. For Drupal 8, I added lots more code analysis, of plugin types and services, but still, the original idea remains: Drupal Code Builder knows how to detect Drupal structures, so it can know more structures than can be hardcoded.
This analysis can get pretty complex. While for hooks, it's just a case of running a regex on api.php files, for detecting information about plugin types, all sorts of techniques are used, such as searching the class parentage of all the plugins of a type to try to guess whether there is a plugin base class. It’s not always perfect, and it could always use more refinement, but it’s a more powerful approach than hardcoding a necessarily finite number of cases. (If only plugin types were declared in some way, or if the documentation for them were systematic in the way hook documentation is, this would all be so much simpler, and much more importantly, it would be more accurate!)
My second buzzword, that UIs for Drupal Code Builder are adaptive, describes the way that neither of the Drush command nor the Drupal module need to know what Drupal Code Builder can build. They merely know the API for describing properties, and how to present them to the user, to then pass the input values to Drupal Code Builder to get the generated code.
This is analogous to the way that Form API doesn’t know anything about a particular form, just about the different kinds of form elements.
This isn’t as exciting or indeed relevant to the end-user, but it does mean that development on Drupal Code Builder can move quickly, as adding new things to generate doesn’t require coordinated releases of software packages for the UI. In fact, I think nearly every new release of Drupal Code Builder has featured some sort of new code generating functionality, while keeping the API the same.
For example, this used to be the UI for adding a route on Drupal and Drush:
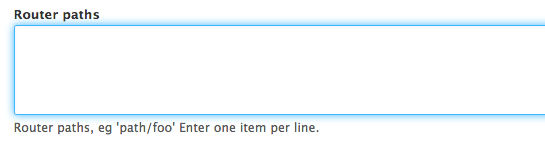
A later release of Drupal Code Builder turned the UI into this, without the Drush command or Module Builder needing their code to be updated:
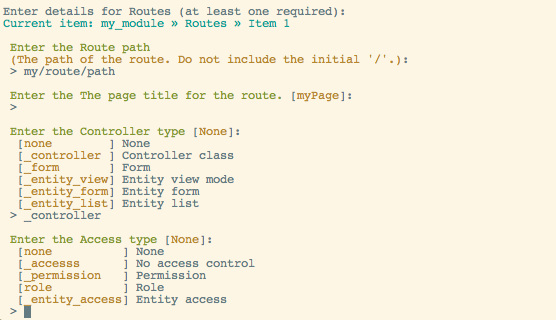
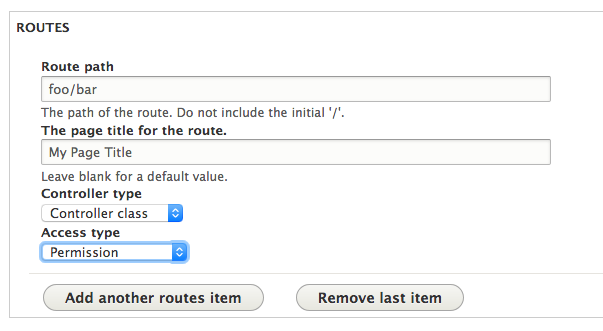
Similarly, an even later version of Drupal Code Builder added code analysis to detect all top-level admin menu items, and so the admin settings form generation now lets you pick where to place the form in the menu.
It would be nice to think that a couple of buzzwords could gain Drupal Code Builder more attention and more users, but I fear that Drupal Console’s generator has got rather more traction in Drupal 8, despite its huge limitation. It’s disappointing that Drush has now added a third code generator to the mix, to even further dilute the ecosystem, and that it’s just as limited by hardcoding.
So where do we go from here?
Well, people get attached to UIs, but they don’t care much about what powers them, especially in this day and age of Composer, where adding dependencies no longer creates an imposition on the end-user.
So I suggest the following: the code analysis portion of Drupal Code Builder could be extracted to a new package. It doesn’t depend on anything on the code generation side, so that should be fairly simple. It provides an API that supports analysis being run in batches, which could maybe do with being spruced up, but it’s good enough for a 1.0.0 version for now.
Then, any code generating system would be able to use it. Both Console and Drush could replace their hardcoded lists of hooks and plugins with analytical data, while keeping the commands they expose to the end-user unchanged.
I’ll be at DrupalEurope in Darmstadt, where I’ll be running a BoF to discuss where we go next with code generation on Drupal.

