There's been a lot of discussion about how we need github-like features on d.org. Will we get them? There's definitely many improvements in the pipeline to the way our issue queues work. Whether we actually need to replicate github is another debate (and my take on it is that I don't think we do).
In the meantime, I think that it's possible to have a good collaborative workflow with what we have right now on drupal.org, with just the issue queue and patches, and git local branches. Here's what I've gradually refined over the years. It's fast, it helps you keep track of things, and it makes the most of git's strengths.
A word on local branches
Git's killer feature, in my opinion, is local branches. Local branches allow you to keep work on different issues separate, and they allow you to experiment and backtrack. To get the most out of git, you should be making small, frequent commits.
Whenever I do a presentation on git, I ask for a show of hands of who's ever had to bounce on CMD-Z in their text editor because they broke something that was working five minutes ago. Commit often, and never have that problem again: my rule of thumb is to commit any time that your work has reached a state where if subsequent changes broke it, you'd be dismayed to lose it.
Starting work on an issue
My first step when I'm working on an issue is obviously:
git pull
This gets the current branch (e.g. 7.x, 7.x-2.x) up to date. Then it's a good idea to reload your site and check it's all okay. If you've not worked on core or the contrib project in question in a while, then you might need to run update.php, in case new commits have added updates.
Now start a new local branch for the issue:
git checkout -b 123456-foobar-is-broken
I like to prefix my branch name with the issue number, so I can always find the issue for a branch, and find my work in progress for an issue. A description after that is nice, and as git has bash autocompletion for branch names, it doesn't get in the way. Using the issue number also means that it's easy to see later on which branches I can delete to unclutter my local git checkout: if the issue has been fixed, the branch can be deleted!
So now I can go ahead and start making commits. Because a local branch is private to me, I can feel free to commit code that's a total mess. So something like:
dpm($some_variable_I_needed_to_examine);
/*
// Commented-out earlier approach that didn't quite work right.
$foo += $bar;
*/
// Badly-formatted code that will need to be cleaned up.
if($badly-formatted_code) { $arg++; }
That last bit illustrates an important point: commit code before cleaning up. I've lost count of the number of times that I've got it working, and cleaned up, and then broken it because I've accidentally removed an important line that was lost among the cruft. So as soon as code is working, I make a commit, usually whose message is something like 'TOUCH NOTHING IT WORKS!'. Then, start cleaning up: remove the commented-out bits, the false starts, the stray code that doesn't do anything, in small commits of course. (This is where you find it actually does, and breaks everything: but that doesn't matter, because you can just revert to a previous commit, or even use git bisect.)
Keeping up to date
Core (or the module you're working on) doesn't stay still. By the time you're ready to make a patch, it's likely that there'll be new commits on the main development branch (with core it's almost certain). And before you're ready, there may be commits that affect your ongoing work in some way: API changes, bug fixes that you no longer need to work around, and so on.
Once you've made sure there's no work currently uncommitted (either use git stash, or just commit it!), do:
git fetch
git rebase BRANCH
where BRANCH is the main development branch that is being committed to on drupal.org, such as 8.0.x, 7.x-2.x-dev, and so on.
(This is arguably one case where a local branch is easier to work with than a github-style forked repository.)
There's lots to read about rebasing elsewhere on the web, and some will say that rebasing is a terrible thing. It's not, when used correctly. It can cause merge conflicts, it's true. But here's another place where small, regular commits help you: small commits mean small conflicts, that shouldn't be too hard to resolve.
Making a patch
At some point, I'll have code I'm happy with (and I'll have made a bunch of commits whose log messages are 'clean-up' and 'formatting'), and I want to make a patch to post to the issue:
git diff 7.x-1.x > 123456.PROJECT.foobar-is-broken.patch
Again, I use the issue number in the name of the patch. Tastes differ on this. I like the issue number to come first. This means it's easy to use autocomplete, and all patches are grouped together in my file manager and the sidebar of my text editor.
Reviewing and improving on a patch
Now suppose Alice comes along, reviews my patch, and wants to improve it. She should make her own local branch:
git checkout -b 123456-foobar-is-broken
and download and apply my patch:
wget PATCHURL
patch -p1 < 123456.PROJECT.foobar-is-broken.patch
(Though I would hope she has a bash alias for 'patch -p1' like I do. The other thing to say about the above is that while wget is working at downloading the patch, there's usually enough time to double-click the name of the patch in its progress output and copy it to the clipboard so you don't have to type it at all.)
And finally commit it to her branch. I would suggest she uses a commit message that describes it thus:
git commit -m "joachim's patch at comment #1"
(Though again, I would hope she uses a GUI for git, as it makes this sort of thing much easier.)
Alice can now make further commits in her local branch, and when she's happy with her work, make a patch the same way I did. She can also make an interdiff very easily, by doing a git diff against the commit that represents my patch.
Incorporating other people's changes to ongoing work
All simple so far. But now suppose I want to fix something else (patches can often bounce around like this, as it's great to have someone else to spot your mistakes and to take turns with). My branch looks like it did at my patch. Alice's patch is against the main branch (for the purposes of this example, 7.x-1.x).
What I want is a new commit on the tip of my local branch that says 'Alice's changes from comment #2'. What I need is for git to believe it's on my local branch, but for the project files to look like the 7.x-1.x branch. With git, there's nearly always a way:
git checkout 7.x-1.x .
Note the dot at the end. This is the filename parameter to the checkout command, which tells git that rather than switch branches, you want to checkout just the given file(s) while staying on your current branch. And that the filename is a dot means we're doing that for the entire project. The branch remains unchanged, but all the files from 7.x-1.x are checked out.
I can now apply Alice's patch:
wget PATCHURL
patch -p1 < 123456.2.PROJECT.foobar-is-broken.patch
(Alice has put the comment ID after the issue ID in the patch filename.)
When I make a commit, the new commit goes on the tip of my local branch. The commit diff won't look like Alice's patch: it'll look like the difference between my patch and Alice's patch: effectively, an interdiff. I now make a commit for Alice's patch:
git commit -m "Alice's patch at comment #2"
I can make more changes, then do a diff as before, post a patch, and work on the issue advances to another iteration.
Here's an example of my local branch for an issue on Migrate I've been working on recently. You can see where I made a bunch of commits to clean up the documentation to get ready to make a patch. Following that is a commit for the patch the module maintainer posted in response to mine. And following that are a few further tweaks that I made on top of the maintainer's patch, which I then of course posted as another patch.
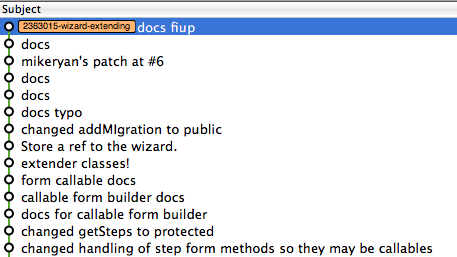
(Notice how in a local branch, I don't feel the need to type terribly accurately for my commit messages, or indeed be all that clear.)
Improving on our tools
Where next? I'm pretty happy with this workflow as it stands, though I think there's plenty of scope for making it easier with some git or bash aliases. In particular, applying Alice's patch is a little tricky. (Though the stumbling block there is that you need to know the name of the main development branch. Maybe pass the script the comment URL, and let it ask d.org what the branch of that issue is?)
Beyond that, I wonder if any changes can be made to the way git works on d.org. A sandbox per issue would replace the passing around of patch files: you'd still have your local branch, and merge in and push instead of posting a patch. But would we have one single branch for the issue's development, which then runs the risk of commit clashes, or start a new branch each time someone wants to share something, which adds complexity to merging? And finally, sandboxes with public branches mean that rebasing against the main project's development can't be done (or at least, not without everyone know how to handle the consequences). The alternative would be merging in, which isn't perfect either.
The key thing, for me, is to preserve (and improve) the way that so often on d.org, issues are not worked on by just one person. They're a ball that we take turns pushing forward (snowball, Sisyphean rock, take your pick depending on the issue!). That's our real strength as a community, and whatever changes we make to our toolset have to be made with the goal of supporting that.